Los artículos mediocres, o incluso falsos, escritos por grandes modelos de lenguaje [o modelo extenso de lenguaje] (LLM) están causando estragos entre los científicos, pero solo porque la industria editorial científica se pudre por sí sola.
Enrico Casu S., 6 de diciembre de 2025
Según Scientific American, a mediados de 2024 se escribieron al menos 60 000 artículos científicos utilizando grandes modelos lingüísticos. Esa cifra no es menor en la actualidad, y los procesos de selección y revisión por pares existentes no pueden detectar todos los errores y problemas que se derivan de ello.
La publicación de datos fraudulentos es motivo de medidas disciplinarias y de pérdida de confianza para el investigador individual, pero las editoriales, las universidades y los gobiernos han creado desde hace mucho tiempo importantes incentivos para que florezca la ciencia basura, supuestamente en nombre de la eficiencia.
A los científicos les encantan los LLM
Se ha vuelto bastante difícil encontrar personas en el mundo académico que nunca hayan utilizado grandes modelos lingüísticos en su trabajo, ya sea en ciencias, tecnología, ingeniería y matemáticas, en ciencias sociales o en humanidades. La imagen estereotipada de alguien con una bata blanca manejando equipos caros en una mesa de trabajo refleja solo una pequeña parte del trabajo de un investigador, y solo en determinados campos.
Gran parte de la jornada laboral de cualquier investigador consiste en leer mucho, escribir mucho y preparar bastantes presentaciones. Dado que este es el caso, las personas que se dedican a esta profesión suelen haber aceptado los LLM sin mucha resistencia.
Algunas herramientas de IA, como Consensus, basada en GPT 4, ofrecen servicios específicamente diseñados para ayudar en estas tareas algo rutinarias, buscando artículos a partir de consultas en lenguaje natural en lugar de palabras clave, y sintetizando páginas de escritos científicos repetitivos (y algo descuidados) en fragmentos más concisos.
Las imágenes generadas por IA se utilizan por todas partes en carteles y presentaciones, especialmente por parte de los profesores de más edad. Esto tampoco debería sorprender, teniendo en cuenta que las herramientas especializadas para gráficos vectoriales específicos de cada campo pueden tener suscripciones bastante elevadas (Biorender, por ejemplo, cuesta a partir de 35 dólares al mes), por no hablar de los ilustradores profesionales.
Luego está la barrera lingüística. El inglés es el idioma de la investigación, pero no necesariamente el idioma de los investigadores. Hasta hace unos años, era bastante común que alguien del laboratorio que dominara el inglés revisara los manuscritos de todo el equipo. Ahora, los borradores pueden pasar por un chatbot para reformularlos o incluso traducirlos desde la lengua materna del autor.
Dependiendo de lo perezoso o desesperado que sea el usuario, puede que se limite a proporcionar el conjunto de datos y una breve descripción del experimento y deje que el modelo escriba por él. Al fin y al cabo, los resultados mediocres no son motivo de preocupación, ya que la redacción del autor podría no ser mucho mejor. Además, nadie va a leer la letra pequeña; van a pedirle a un LLM que se la resuma.
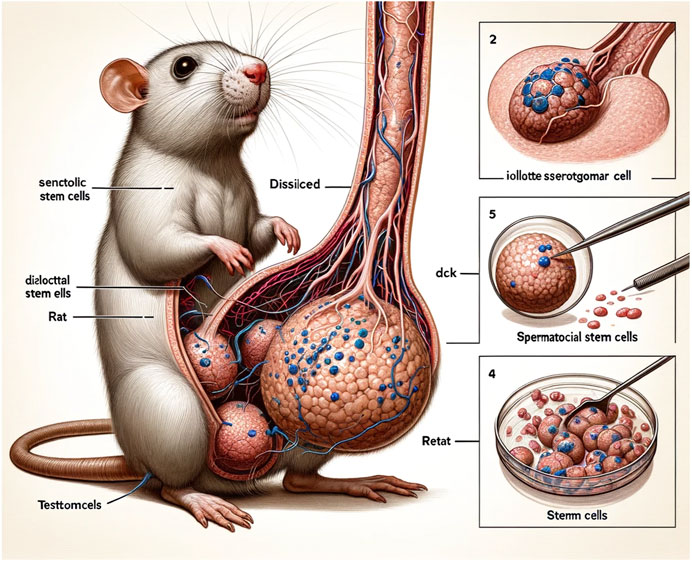
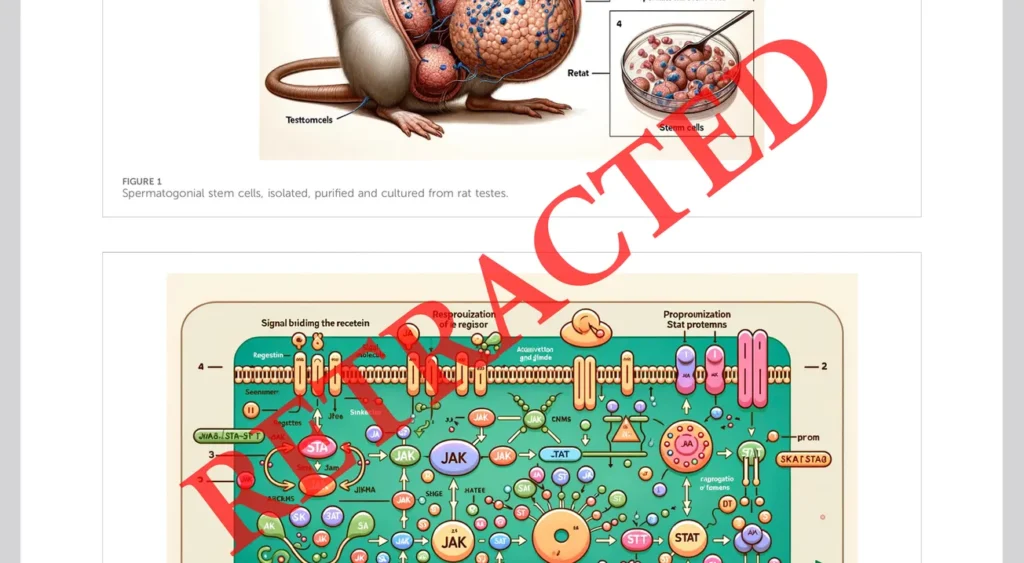
Luego está lo grotesco y lo absurdo. Aunque no han faltado ejemplos de ambos, el más famoso proviene de un artículo que trata sobre la comunicación intracelular en los espermatozoides, que incluía unas ilustraciones ridículas realizadas con Midjourney.
Se supone que las imágenes representan los métodos y los resultados de los estudios, una tarea imposible dada la incapacidad de los algoritmos de difusión estable para escribir texto en ese momento, y por la confusión general y la naturaleza absurda de las representaciones.
Por supuesto, la verdadera razón de la fama de este artículo se encuentra en la Figura 1, en la que aparece un ratón diseccionado, con un falo anatómicamente improbable (podemos estar seguros de que se trata de un falo, ya que la figura ilustra cómo se obtuvieron cultivos celulares a partir de testículos de rata).
El artículo se difundió rápidamente en Twitter/X y fue retirado pocos días después de su publicación. La nota de retractación no hace mención alguna al texto real del artículo, solo a las ilustraciones generadas por IA, por lo que no está claro si los hallazgos y los datos eran legítimos o no. En cualquier caso, los autores nunca volvieron a publicar en la misma revista, ni posiblemente en ninguna otra.
Tras su publicación, se plantearon dudas sobre la naturaleza de las figuras generadas por IA. El artículo no cumple con los estándares de rigor editorial y científico de Frontiers in Cell and Developmental Biology, por lo que ha sido retirado.
Aunque es tentador restar importancia a incidentes como este calificándolos de malicia o pereza, y considerar la rápida retractación como un buen control de calidad, el problema es mucho más sistémico de lo que parece al público en general. Si bien los LLM y la generación de imágenes mediante IA están agravando los problemas con los artículos y datos basura, existen incentivos y cuestiones que tienen su origen en los detalles más concretos de la carrera de los investigadores.
Cómo se hace ciencia
Todos los profesores, estudiantes de doctorado, posdoctorados e investigadores, prácticamente sin excepción, saben lo que significa «publicar o perecer». No es una expresión nueva, ya que se remonta a casi un siglo atrás, pero sigue aplicándose en diversos grados en todos los ámbitos de la academia y la investigación privada.

En pocas palabras, hay más traseros que sillas tanto en las universidades como en los institutos. Cuando un investigador busca una beca o un trabajo, su trabajo debe ser evaluado de alguna manera, y las únicas personas competentes para hacerlo suelen ser los propios colegas del candidato. En aras de la imparcialidad, los gobiernos, las universidades y los financiadores han adoptado una serie de medidas objetivas del rendimiento de sus investigadores, basadas principalmente en el número de publicaciones y el número de citas.
La lógica detrás de estas métricas es bastante sencilla: si un investigador es un trabajador que produce conocimiento, en forma de artículos científicos, entonces su productividad se mide por la cantidad de artículos que puede producir; y si los artículos son de cierta calidad, alguien los citará en su propio trabajo.
Como afirma la ley de Goodhart, y como ilustra excelentemente xkcd, el favorito de los investigadores autistas, cuando una métrica se convierte en un objetivo, deja de ser una buena métrica. De hecho, el sistema se ha llenado tanto de explotadores que el objetivo se ha separado por completo de la calidad.
Cuando el mundo académico era un círculo cerrado de unos pocos privilegiados, los artículos científicos eran una herramienta para que los científicos se comunicaran con sus colegas y les informaran de sus descubrimientos antes de que estos aparecieran en un libro. Las bibliotecas universitarias compraban revistas para sus estudiantes e investigadores, que encontraban artículos que describían el descubrimiento de un fenómeno de forma coherente y exhaustiva, de principio a fin.
Cortar salami es exactamente lo contrario, y es omnipresente. Dado que los investigadores tienen incentivos para publicar más y los recursos siguen siendo los mismos (o, más comúnmente, se reducen), el trabajo y los gastos que habrían dado lugar a un manuscrito completo se distribuyen entre varios, cada uno de ellos meticulosamente específico. El salami sigue siendo el mismo, pero hay que cortarlo más fino, o si no…
Así, el estudio de un gen concreto en las células cancerosas podría dividirse en un artículo para probar el tratamiento A, otro para probar los tratamientos B y C y compararlos con el artículo anterior, otro para establecer la función de ese gen y sus interacciones in vitro, otro en un modelo animal, otro para comparar diferentes poblaciones y, por último, una revisión o metaanálisis para que el estudiante universitario también tenga una publicación en su currículum.
No solo se cuentan por separado, sino que también se citarán por separado cuando otros equipos discutan el tema. El resultado es que solo la revisión final traza una narrativa coherente que hace que el tema sea realmente comprensible.
Quizás más famoso, la presión de publicar o perecer es el principal motor de la crisis de replicación, en la que alrededor de un tercio de los hallazgos científicos (especialmente en psicología y medicina) no pudieron verificarse de forma independiente. Los resultados no significativos no son interesantes, los artículos poco interesantes no se publican, y eso no es una opción para algunos, por lo que el método científico deberá ajustarse en consecuencia. Se han puesto en marcha varias medidas de protección desde que el tema comenzó a recibir atención, pero la ciencia basura no proviene únicamente del interior del laboratorio.
Los editores son realmente malvados
Aparte de los administradores mal informados y los científicos con exceso de trabajo, hay alguien que realmente está ganando mucho dinero con toda esta situación. Las publicaciones científicas están dominadas por un oligopolio de unas pocas empresas extremadamente rentables que controlan el mercado, a saber, Elsevier, Springer Nature, Wiley-Blackwell, Taylor & Francis y Sage Publishing.
Mientras que en el periodismo los autores cobran por los artículos que escriben, en las publicaciones científicas los investigadores (o, por lo general, las universidades) tienen que pagar a las revistas por la revisión, la publicación y el acceso abierto. Si el autor decide no pagar esto último, los lectores tendrán que pagar para acceder al artículo, lo que reduce en gran medida las posibilidades de que sea leído o citado.
La mayoría de las revistas cobran entre dos y seis mil euros por el acceso abierto, y las publicaciones de élite como Nature superan los diez mil euros. Es habitual que la mitad del presupuesto de un proyecto de investigación se destine a pagar las tarifas de publicación.

En este ecosistema, los depredadores son las llamadas revistas depredadoras, que aceptan cualquier manuscrito que se les envía sin apenas revisarlo, a veces a precios exorbitantes. A menudo, esta es una opción para que los charlatanes y los vendedores de humo consigan cierta apariencia de credibilidad, pero en su mayoría se centran en investigaciones legítimas.
Existen varias herramientas para distinguir a los editores legítimos de los depredadores, siendo la más consolidada el factor de impacto y sus derivados, pero estas también terminan reforzando el oligopolio preexistente y reciben muchas críticas sobre su eficacia.
Para ser claros, dichas publicaciones tradicionales, con su enorme cuota de mercado y sus recursos, tampoco son garantía de calidad. El artículo sobre la rata fálica surrealista se publicó en una revista del grupo Frontiers Media, que goza de buena reputación.
Aunque la retractación fue rápida, el artículo tuvo que esperar 40 días para el control de calidad, que suele incluir la revisión por parte de expertos y la revisión por pares. Cabe mencionar que, a pesar de las astronómicas tarifas, los revisores por pares suelen ser voluntarios no remunerados.
Solicitar la presentación de revisiones bibliográficas es también una táctica depredadora típica, común a todos los editores, independientemente de su modelo de negocio. Dado que las revisiones se escriben sintetizando artículos preexistentes, los LLM son especialmente adecuados para producirlas de forma rápida y resumida. Con temas especialmente glamurosos o de actualidad, esto puede acabar inflando significativamente la literatura científica.
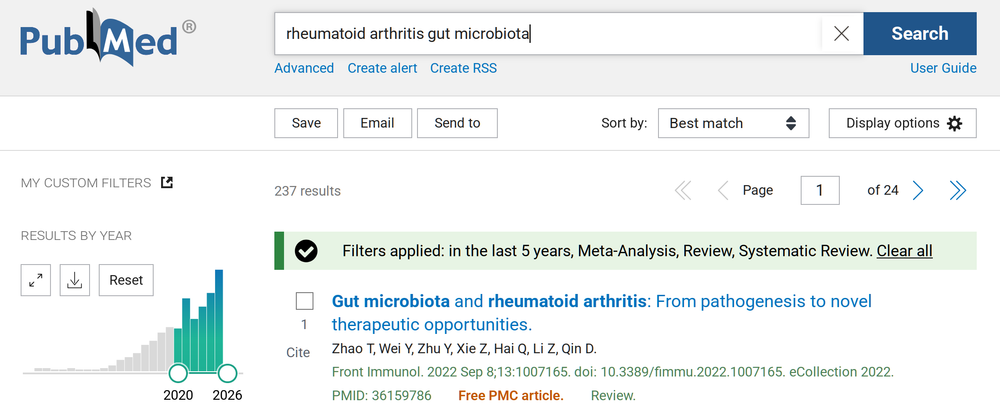
Por ejemplo, al introducir la frase de búsqueda «artritis reumatoide microbiota intestinal» en el agregador PubMed y restringir la búsqueda a los últimos cinco años, se obtienen 558 resultados, de los cuales 237 son revisiones o metaanálisis. El interés de las editoriales (y las empresas farmacéuticas) ha provocado una saturación de la literatura especializada sobre el tema, de modo que casi la mitad del material publicado son descripciones redundantes de la otra mitad, los datos reales.
Los científicos han estado luchando contra estos incentivos tóxicos a su manera. Cabe señalar que la mayoría de los investigadores sienten una verdadera pasión por su campo, por lo que están muy insatisfechos incluso con los mecanismos que podrían aceptar sin perder dinero.
Una iniciativa especialmente notable y principalmente popular es el movimiento de datos abiertos, que promueve y persigue la publicación frecuente de conjuntos de datos de experimentos de forma gratuita y estandarizada. Este modelo permite a los científicos compartir rápidamente sus hallazgos, ponerlos a disposición para su examen y para nuevas investigaciones, al tiempo que reduce el tiempo y el dinero que se gastan en las publicaciones tradicionales. No hace falta decir que el movimiento asume una fuerte filosofía FOSS.
China y la India no son diferentes, solo que son enormes
Un último factor para comprender la explosión de la ciencia basura proviene de la emergencia de China y la India como potencias científicas. Para evitar cualquier confusión, su ascenso a la prominencia ha sido netamente positivo para la ciencia y la humanidad.
China está contribuyendo enormemente a la ingeniería y la medicina, y la idea que la mayoría de las personas tienen de la innovación china tiende a reflejar esto con bastante fidelidad. India y Pakistán, aunque suelen estar infravalorados en la cultura general, se encuentran en la peculiar situación de disponer de importantes recursos para la investigación, mientras que un gran porcentaje de su población se enfrenta a problemas propios de la pobreza; por esta razón, ambos países se han convertido en los principales contribuyentes al diagnóstico y tratamiento de enfermedades como la tuberculosis y la lepra, que siguen representando un riesgo potencial para la salud mundial.
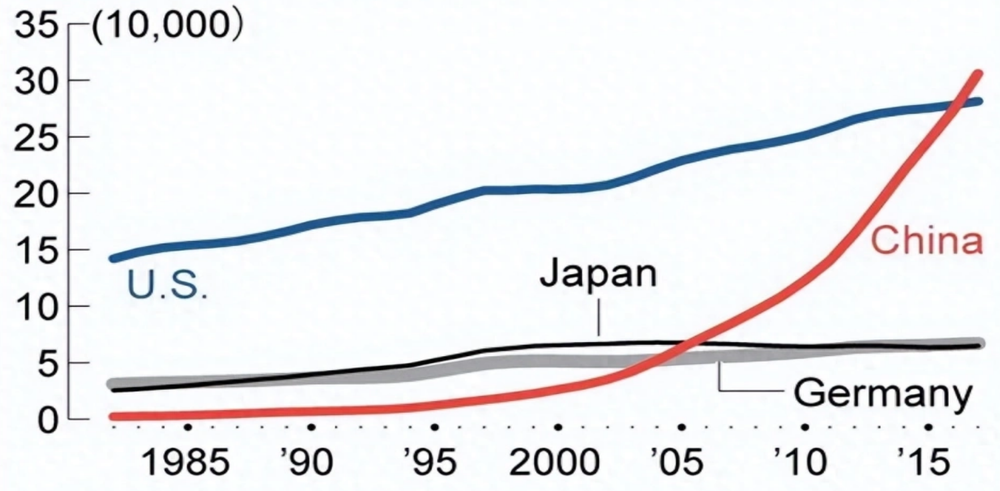
Para que se entienda el alcance de su papel, hasta la década de 1990 los científicos chinos publicaban una cantidad insignificante de artículos. En los últimos diez años, su producción ha superado a la de Estados Unidos, históricamente la fuente más prolífica de literatura científica.
La propia China ha adoptado este tipo de métrica sin reservas y anima a sus estudiantes e investigadores a publicar cada vez más, prometiéndoles mejores oportunidades profesionales basadas en mediciones objetivas similares. En otras palabras, China está adoptando las mismas estrategias de cantidad por encima de calidad que todos los demás han estado utilizando, aunque de forma ligeramente más agresiva, y la India le sigue de cerca.
La barrera del idioma también afecta especialmente a estos países. Muchos investigadores chinos tienen un dominio limitado del inglés. Sus colegas de Deshi suelen tener un mayor dominio del idioma, aunque es posible que solo se sientan cómodos con su dialecto específico del inglés y lo consideren inadecuado para la redacción académica, debido a asociaciones culturales. El inglés académico es un dialecto diferente en sí mismo, muy influenciado por la sintaxis extranjera y la jerga específica, pero es considerablemente más cercano a algunos dialectos británicos y estadounidenses que a los de la India y Pakistán.
Dada la enorme población de China y la India, el impulso institucionalizado para obtener mayores resultados, las necesidades específicas de los propios investigadores chinos e indios, y el hecho de que el mundo académico siga siendo una vía valiosa para la movilidad social en algunos contextos de ambos países, es fácil imaginar cuál puede ser el efecto.
El volumen de publicaciones de estos países es tal que cualquier porcentaje de basura supondrá una gran cantidad de basura, y la IA ha sido especialmente eficaz para acelerar su producción, tanto en Asia como en el resto del mundo.
Grandes caníbales del lenguaje
GPT, junto con otros modelos, se entrenó inicialmente con artículos científicos. De hecho, varias de las primeras peculiaridades del «lenguaje de la IA» se heredan directamente del lenguaje académico: la impersonalidad, el uso de palabras largas y poco comunes de origen latino en lugar de sus equivalentes anglosajones, las listas y los tonos excesivamente entusiastas son muy comunes en los artículos de ciencias, tecnología, ingeniería y matemáticas.
Por lo tanto, si los LLM se entrenan con literatura científica y un porcentaje cada vez mayor de artículos científicos se escribe con LLM, es lógico preguntarse qué consecuencias puede tener esto. Podemos tomar como referencia los modelos de difusión estable cuando comenzaron a utilizar imágenes generadas por IA en su conjunto de datos de entrenamiento, lo que dio lugar a la aparición de un «estilo IA» vagamente definido en los resultados posteriores.
Incluso el tinte amarillo que se hizo famoso el año pasado y que nunca desapareció del todo se atribuye a menudo a los modelos que reciclan sus propios productos, en particular los que imitan el anime del Studio Ghibli.
No está claro cómo se traducirá esto en la producción de texto, pero la repetición y la consolidación de los sesgos están en la mente de todos como un peligro real para la investigación. Al fin y al cabo, se supone que la ciencia se basa en la corrección de errores anteriores. Tampoco está claro qué filtros y controles de calidad se pueden establecer, si es factible detectar eficazmente la IA y si las editoriales están realmente interesadas.
Como es de esperar, la podredumbre proviene de mucho más arriba, y la IA solo se ha podido propagar gracias a un entorno de incentivos perversos.
——————